


No ano passado, uma pesquisa da Forbes Insights com mais de 200 líderes de tecnologia em todo o mundo apontou a falta de dados como a barreira mais significativa para a adoção de IA nas empresas. Não poderia haver uma ideia mais equivocada, na visão de Andrew Ng, fundador e CEO da Landing AI. Muitos dos conjuntos de dados mais valiosos nas organizações são muito pequenos: pense em kilobytes ou megabytes em vez de exabytes.
Setores como manufatura e saúde raramente têm acesso a conjuntos de big data. Um fabricante de automóveis não terá um milhão de imagens de peças defeituosas. Um provedor de saúde não terá um milhão de tomografias computadorizadas de novas doenças como Covid-19. Ainda assim, todos têm muito a ganhar com projetos de Inteligência Artificial.
Ferramentas e técnicas emergentes de IA estão abrindo novas possibilidades para treinar modelos com Small Data. Por exemplo:
- O Few-Shot Learning (FSL) ensina os sistemas de IA a identificar categorias de objetos (rostos, gatos, motocicletas) com base em apenas um ou alguns exemplos, em vez de centenas de milhares de imagens.
- Com Transfer Learning um modelo desenvolvido para uma tarefa é reutilizado como ponto de partida para outro modelo, de outra tarefa. Por meio desta técnica, mil imagens de arranhões em uma variedade de produtos eletrônicos podem ser usadas para treinar um modelo de IA para detectar arranhões em telefones celulares.
- Já no Zero-shot Learning a IA é capaz de prever com precisão o rótulo de uma imagem ou objeto que não estava presente nos dados de treinamento. Ou seja, o sistema é capaz de identificar corretamente coisas que nunca viu antes.
- E o Collective Learning entra em ação quando muitas empresas individuais desejam automatizar o mesmo caso de uso.
Muitas vezes, o melhor caminho para iniciar um projeto de IA é usar os dados que a empresa tem. Isso permitirá à equipe de cientistas priorizar os dados adicionais que precisarão se coletados para melhorar a acurácia dos modelos. O que significa mudar a mentalidade do Big Data para o Good Data. Em vez de muitos dados, ter dados mais adequados, de melhor qualidade, rotulados de forma consistente e com curadoria cuidadosa.
“Para muitos projetos de IA, os modelos de código aberto disponíveis no GitHub, e em outros repositórios, são suficientes para a construção de aplicações. A coisa mais importante que as empresas precisam fazer é criar processos para melhorar a qualidade dos dados disponíveis”, explica Andrew Ng. “Vejo mais empresas fracassarem começando com projetos muito grandes do com projetos menores, que as ajudam a aprender como é desenvolver e usar IA”, diz ele.
Portanto, tudo bem começar pequeno, sempre mantendo o foco nos problemas de negócios e no cliente, não na tecnologia. Porque contexto também é importante, quando se trata de extrair inteligência aplicando IA aos dados. Construir o maior data lake possível não será útil se a empresa não não souber o que está tentando encontrar.

Muitos pesquisadores sustentam que, na maioria das vezes, a IA se torna ainda mais inteligente e poderosa se tiver a capacidade de ser treinada com Small Data. Até porque, em última análise, a IA é sobre o domínio do conhecimento, não o processamento de dados. Envolve dar a uma máquina o conhecimento necessário para realizar uma tarefa.
Na opinião deles, dominar Small Data será essencial para o avanço da IA. Até porque, embora o conceito de Small Data tenham começado no mundo do marketing, ele é cada vez mais importante em todos os tipos de setores e empresas, independente do porte.
Na verdade, de acordo com o dinamarquês Martin Lindstrom, autor do livro “Small Data: Como poucas pistas indicam grandes tendências“, qualquer empresa que deseje obter informações estratégicas a partir de pequenos dados – tanto sobre clientes quanto sobre tendências de mercado – pode fazê-lo levando em consideração alguns aspectos como correlação e causalidade.
O quanto é suficiente?
O tamanho mínimo do conjunto de dados pode depender de muitos fatores, como a complexidade do modelo que está sendo construído, o desempenho desejado e o problema específico a ser resolvido.
Digamos que sua equipe de cientistas de dados tenha trabalhado em um modelo e tenha alcançado o melhor desempenho possível com os dados disponíveis, mas aquém do necessário para solucionar o problema se negócio. O que fazer? Coletar dados diferentes? Coletar mais dados iguais? Coletar ambos para otimizar seu tempo e esforços?
Essas perguntas podem ser respondidas por um diagnóstico do modelo e dos dados por meio de uma curva de aprendizado (gráfico abaixo, da Researchgate), que mostra como o desempenho do modelo aumenta à medida que mais pontos de dados são adicionados.
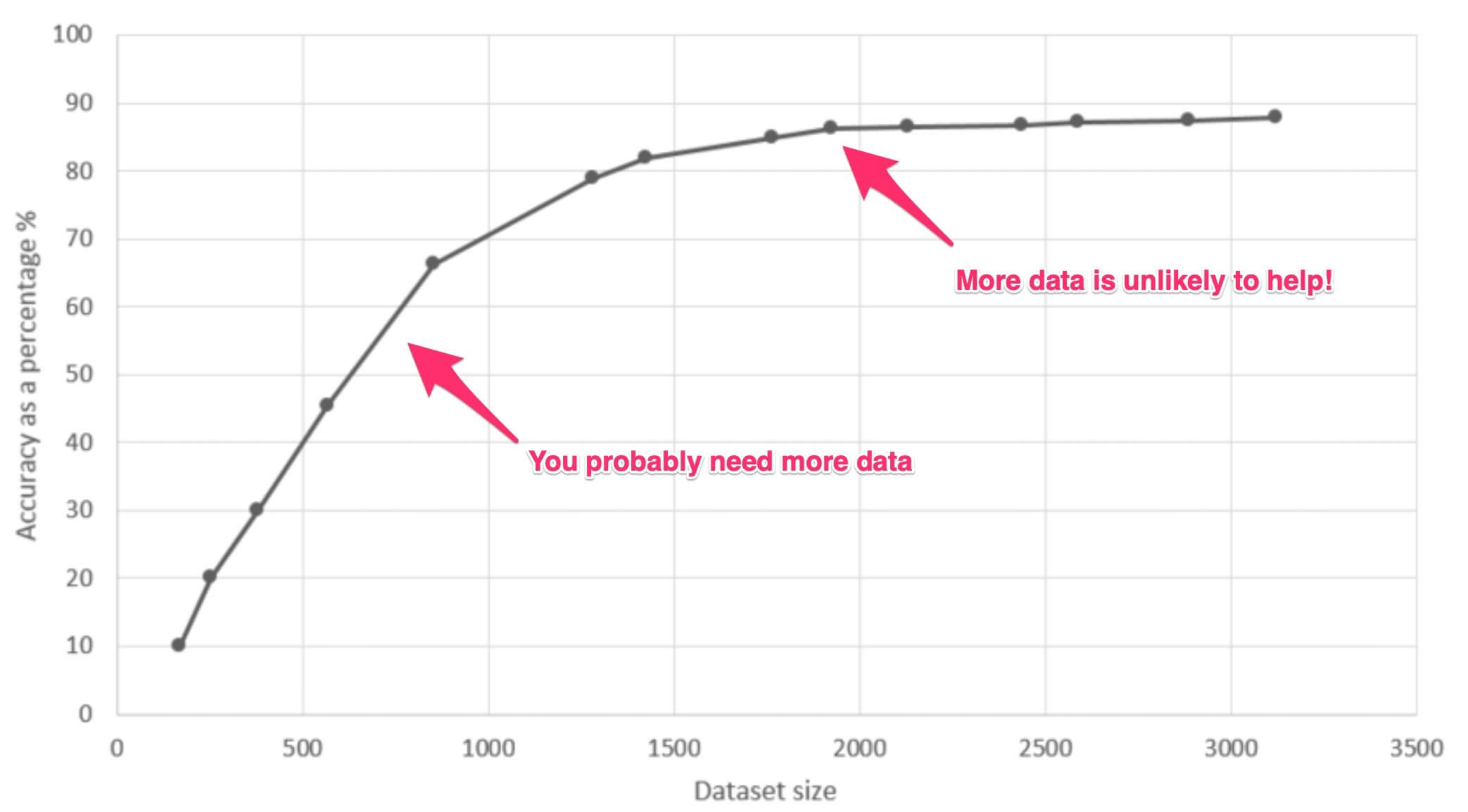

Caso haja a necessidade de mais dados, existem diferentes estratégias a serem consideradas, dependendo do problema em questão e da sua situação:
- Se coletar mais dados não for possível, um dos recursos mais comuns é recorrer aos dados sintéticos. Outro é recorrer à penalizar dados “não importantes” para dar mais peso aos pontos de dados relevantes, reduzindo a complexidade do modelo.
- Já se coletar mais dados for possível, qualificá-los (através de rotulaagem correta).
Cada empresa possui um conjunto de dados com valor exclusivo para seus negócios. Frequentemente, entretanto, há uma desconexão entre os dados e o valor. Os dados capturados não são claros, precisos ou acionáveis.
Uma estrutura útil para controlar o caos de dados e extrair pequenos dados de alta precisão concentra-se nos ciclos de vida de clientes, parceiros e fornecedores.
Possíveis casos de uso
Pense na descoberta de medicamentos, na recuperação de imagens industriais, no design de novos produtos de consumo, na detecção de peças defeituosas em linhas de produção, etc.
No monitoramento cardíaco remoto, por exemplo, o batimento cardíaco de cada paciente é algo único. As máquinas precisam aprender rapidamente, com base nos dados de um único paciente, como detectar quando algo diferente está acontecendo.
Também podemos obter uma visão precisa da personalidade, dos hábitos e das motivações de um indivíduo apenas com poucos dados. E otimizar produtos e serviços para ele.
Enquanto o Big Data analisa comportamentos e padrões preditivos em grande escala, o Small Data fornece informações qualitativas. Pistas mínimas – às vezes inesperadas – que as marcas devem usar para identificar oportunidades, converter em produtos e serviços inovadores, ou/e em insigths valiosos.
A maior vantagem competitiva do Small Data associado à IA não é tanto a automação. Vem do fator humano. Como a IA desempenha um papel cada vez maior no treinamento de habilidades de funcionários, sua capacidade de aprender com conjuntos de Small Data permitirá que eles incorporem sua experiência nos sistemas de treinamento, melhorando-os continuamente, transferindo suas habilidades de forma eficiente para outros trabalhadores.
Profissionais sem conhecimentos técnicos de Ciência de Dados podem ser transformados em treinadores de IA, permitindo que as empresas apliquem e escalonem suas vastas reservas de conhecimento, até aqui inexploradas.
Lembre-se, a IA é prescritiva por natureza. Quanto mais estreitamente pudermos definir o objetivo de negócios e quanto mais contextualmente preciso for nosso conjunto de dados, maior será a probabilidade de resultados significativos.
“Quando um sistema não está funcionando bem, muitas equipes tentam instintivamente melhorar o código. Mas, para muitas aplicações práticas, é mais eficaz se concentrar na melhoria dos dados”, sustenta Andrew Ng.
Aqui estão algumas regras que Ng propõe para ajudar a implantar ML com eficiência:
- A tarefa mais importante dos MLOps é disponibilizar dados de alta qualidade.
- A consistência da rotulagem é fundamental. Pode haver várias maneiras de rotular e, mesmo que sejam boas sozinhas, a falta de consistência pode deteriorar o resultado.
- A melhoria sistemática da qualidade dos dados em um modelo básico é melhor do que perseguir os modelos de última geração com dados de baixa qualidade.
- Em caso de erros durante o treinamento, adote uma abordagem centrada nos dados.
- Com a visão centrada em dados, há espaço significativo para melhorias em problemas com conjuntos de dados menores (<10k exemplos).
- Ao trabalhar com conjuntos de dados menores, ferramentas e serviços para promover a qualidade dos dados são essenciais.